
Why ensemble models perform better than individual models?
A single model is known to make errors. If we make models that make different errors, the models can complement each other, and the error can be reduced. So, instead of training one model for the given problem, we can train multiple of them. But how do we build models that make different errors?
- Motivation for Ensembling
- What is Bagging?
- Variance of the Ensemble Model
- Random Forests
- Appendix
- References
Motivation for Ensembling
It is known that the mean squared error of the model $f$ in predicting the target $Y$ for an input data point $x$ can be decomposed into bias and variance terms:
\[\text{MSE}\left(f(x)\right) = \text{bias}^2 \left(f(x) \right) + \text{var} \left(f(x) \right) + \text{Noise}\]That is, the model error can be decomposed into the square of the bias of the model + variance of the model + some irreducible error.
Variance of the model:
The “variance of the model” refers to the average amount by which the prediction at a data point $x$ would change if we predicted it using models trained on different training data sets sampled from the same underlying distribution. In technical terms,
\[\text{Var}(f(x)) = \mathbb{E}_{\mathcal{D}} \left[ \left( f(x) - \mathbb{E}_{\mathcal{D}} \left[ f(x) \right] \right)^2 \right]\]where the expectation is taken over the training data sets $\mathcal{D}$ sampled from the same underlying distribution.
- For a given specific training set, we build a model $f$. This gives a single prediction value $f(x)$ for a given input $x$.
- Now, suppose we got a different training set (from the same underlying distribution), and we build a model on that. We get a different prediction value for the same input $x$.
- On repeating this process many times, we get a distribution of predictions for the same input $x$. The variance of this distribution is the variance of the model at $x$.
Individual models suffer from high variance. Different training data gives different models which leads to different results. In the bias-variance decomposition of the error, the variance term has two terms: the model $f$ which is trained on a given dataset and the aggregated/average model $\mathbb{E}_{\mathcal{D}} \left[ f(x) \right]$ which represents the expected prediction over all possible datasets. The variance measures the deviation between these two. If we can ensure that our model prediction is close to the expected prediction, we can reduce the variance, thus reducing the overall error of the model. This can be achieved by averaging the predictions from multiple models which are trained on different datasets. This is the motivation for ensembling.
But in practice, we are given only one training dataset. We don’t have multiple datasets to train multiple models. To overcome this, we create multiple datasets by sampling with replacement.
But how do we construct models that make different errors, and thus complement each other? There are two techniques for achieving it: Bagging and Boosting. Bagging is discussed in this article, and boosting will be discussed separately.
TIP
The individual models that go into ensemble do not need to be very good; they just have to be better than chance. Thus, every individual model in an ensemble is called a weak learner. As long as they are better than chance, the ensembles are always guaranteed to give dramatic improvements in performance by reducing the variance.
What is Bagging?
Bagging stands for Bootstrap Aggregation. In bagging, we simply sample the given training data with replacement to create multiple datasets (called as bootstrap samples) and train multiple models. Suppose the dataset $\mathcal{D} = {x_1, \dots, x_N}$ contain $N$ samples. We create $B$ training sets by sampling with replacement so that each new dataset $D_b$ has $N$ samples.
- The probability of a sample $x_i$ being picked in one draw is $\frac{1}{N}$.
- The probability of a sample $x_i$ being picked in one draw is $1-\frac{1}{N}$.
Since $N$ draws are independent (because of replacement), the probability of $x_i$ never appearing in $D_b$ is $ \left( 1-\frac{1}{N} \right)^N$. As $N \to \infty$,
\[\left( 1-\frac{1}{N} \right)^N \to e^{-1}\]So approximately, $P(x_i \notin D_b) \approx \frac{1}{e} \approx 0.368$. This is a well-known bootstrap result:
- In each bootstrap sample, roughly 36.8% of the original samples are left-out. Equivalently, about 63.2% of unique original samples appear at least once. This brings an implicit regularization effect; because it creates an implicit validation data.
Now, we have $b=1, \dots, B$ datasets each of size $N$. We can train $B$ independent models: $f_1(x), f_2(x), \dots, f_B(x)$. The models can be trained independently and in parallel. The final prediction for the input $x$ is
\[\hat{y}_{\text{bag}} = \frac{1}{B} \sum_{b=1}^B f_b(x)\]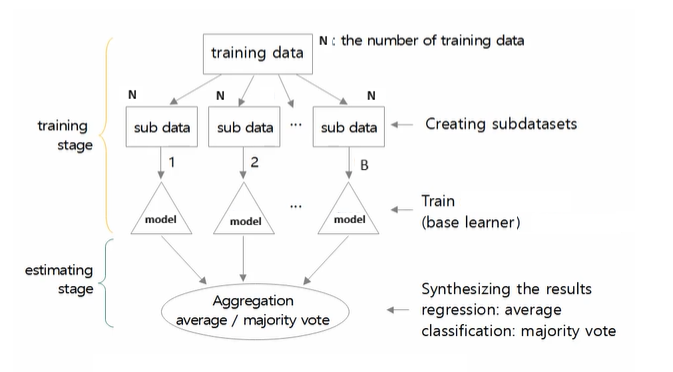
In the inference stage, a test data point $x$ is fed into all the trained models. We get prediction from all these $B$ models. We then combine the results by taking
- Average (in case of regression or if the classifiers output probability)
- Majority vote (in case of classification)
Note that every individual model is given the same weight while aggregating the results.
Note
In bagging, we typically train each model using the same algorithm with the same hyperparameter configurations. The diversity between the models is driven entirely by the random data sampling (bootstrapping).
The injected randomness in the dataset creation process results in uncorrelated models (non-identical models). Thus, we ensure diversity among the models, and model errors complement each other. On combining them, we can improve the overall model generalization.
Variance of the Ensemble Model
The primary objective of ensembling is to reduce the variance of the model so that the overall error associated with the model can be reduced. This section provides a mathematical proof that ensembling reduces the variance of the model, and also the condition under which the variance of the ensemble is strictly smaller than the variance of the individual model. Thereby, providing the motivation for one of the well-known bagging-based ensemble models, Random Forests.
Let $x$ be a fixed data point, and the $i$th model is $f_i$. Suppose $z_i$ represents a random variable corresponding to the prediction of this $i$th model on $x$. Then,
\[z_i = f_i(x)\]Because the training set used to build $f_i$ is random (e.g., a bootstrap sample), $f_i$ itself is random, and therefore $z_i$ is a random variable. For instance, assume that our training dataset has three data points $ {x_1, x_2, x_3 }$. Possible bootstrap samples include
- ${x_1, x_1, x_1 }$
- ${x_1, x_2, x_1 }$
- ${x_2, x_2, x_1 }$, etc.
There are $3^3 = 27$ possible ordered samples, and each has an equal probability of $\left(\frac{1}{3} \right)^3 = \frac{1}{27}$ to be selected. In general, probability of getting a particular ordered bootstrap sample is $\left(\frac{1}{N} \right)^N$. We get bootstrap samples $D_1, \dots, D_B$ and train $f_1, \dots, f_B$ models. That is,
- We draw a bootstrap sample from the given training data
- Train a model using the same algorithm and hyperparameters
- Evaluate it at $x$
Suppose we repeatedly do this process many times, then the prediction of the first model $f_1$ at $x$ would vary depending on which bootstrap sample it received. Thus,
\[z_i = f_i(x)\]has a probability distribution. We have $B$ such random variables, $z_1, \dots, z_B$, because we have $B$ models trained.
Since every model is trained on the data sampled from the same distribution, the distribution of its prediction at $x$ will be the same. That is, the random variables $z_1, \dots, z_B$ are identically distributed. But note that they are not independent because we have bootstrap samples that overlap. When we do random sampling with replacement and create multiple datasets, our i.i.d assumption across these data sets will be broken. The created data sets will overlap with each other. As they overlap, the resulting models are usually correlated. That is, the prediction (and so the error) made by one model is correlated with the prediction (and so the error) made by another model.
\[\text{cov}(z_i, z_j) \ne 0\]So, we say that $z_1, \dots, z_B$ are identically distributed but correlated, which can be formulated as:
\[\begin{align*} \mathbb{E}[z_i] & = \mu \\ \text{var}(z_i) & = \sigma^2 \hspace{1cm} \forall i =1, \dots, B \\ \text{corr}(z_i, z_j) & = \rho \hspace{1cm} (i \ne j) \end{align*}\]$\rho$ denotes the correlation between individual models. We know that
\[\begin{align*} \text{corr}(z_i, z_j) & = \frac{\text{cov}(z_i, z_j)}{\sigma_i \sigma_j} = \frac{\text{cov}(z_i, z_j)}{\sigma^2} \\ & \implies \text{cov}(z_i, z_j) = \rho \cdot \sigma^2 \end{align*}\]From the definition of ensemble, we have
\[\bar{z} = \frac{1}{B} \sum_{i=1}^B z_i\]Then, the variance of the ensemble is:
\[\begin{align*} \text{var}(\bar{z}) & = \text{var}\left( \frac{1}{B} \sum_{i=1}^B z_i \right) \\ & = \frac{1}{B^2} \text{var}\left(\sum_{i=1}^B z_i \right) \\ & = \frac{1}{B^2} \left( \sum_{i=1}^B \text{var}( z_i ) + \sum_{i \ne j} \text{cov}(z_i, z_j) \right) \\ & = \frac{1}{B^2} \left( B\cdot \sigma^2 + \sum_{i \ne j} \text{cov}(z_i, z_j) \right) \\ \end{align*}\]There are $B$ number of $z_i$’s. So, there are $B(B-1)$ ways to select an ordered pair. Then,
\[\begin{align*} \text{var}(\bar{z}) & = \frac{1}{B^2} \left( B\cdot \sigma^2 + B(B-1) \cdot \rho \cdot \sigma^2 \right) \\ & = \frac{1}{B^2} \left( B\sigma^2 + B^2 \rho \sigma^2 - B \rho \sigma^2 \right) \\ & = \frac{1}{B^2} \left( B^2 \rho \sigma^2 + B\sigma^2 (1-\rho)\right) \\ & = \rho \sigma^2 + \left( \frac{1-\rho}{B} \right) \sigma^2 \\ & = \sigma^2 \left( \rho + \frac{1-\rho}{B} \right) \\ \end{align*}\]Define:
\[A = \left( \rho + \frac{1-\rho}{B} \right)\]We want $A \leq 1$ so that the variance of the ensemble is less than or equal to the variance of the individual model. $A$ can be rewritten as:
\[\begin{align*} A & = \left( \frac{B \rho + 1-\rho}{B} \right) \\ & = \frac{(B - 1)\rho + 1}{B} \\ & = \frac{(B - 1)\rho}{B} + \frac{1}{B} \\ & = \frac{1}{B} + \left(1-\frac{1}{B} \right) \rho \\ \end{align*}\]Then
\[\begin{align*} 1-A & = 1- \frac{1}{B} - \left(1-\frac{1}{B} \right) \rho \\ & = \left( 1- \frac{1}{B} \right) (1- \rho) \\ \end{align*}\]We want $1-A \geq 0$, i.e., we want both the RHS terms to be $\geq 0$.
- Since $B \geq 1$, $\left( 1- \frac{1}{B} \right)$ is always $\geq 0$.
- The correlation coefficient $\rho$ satisfies $\leq 1$, so $(1- \rho)$ is always $\geq 0$.
which implies $1-A \geq 0 \implies A \leq 1$.
When do we get equality, i.e., $A=1$?
There are two cases in which this can happen:
- When $B=1$: no ensemble, then $\text{var}(\bar{z}) = \sigma^2$ (same as the variance of the individual classifier). Or,
- When $\rho=1$: all models are perfectly correlated. That is, when all the models are built using the same data, same algorithm and the same hyperparameters. Averaging identical models gives no variance reduction.
When is the variance strictly smaller, i.e., $A < 1$?
Whenever $B > 1$ and $\rho < 1$, then $\text{var}(\bar{z}) < \sigma^2$. This proves that ensembling always reduces the variance of the model, thus reducing the overall error of the model. In summary, to reduce the variance of the model, we should:
- Increase $B$ - increase the number of models
- Decrease $\rho$ - decrease the correlation among the models. That is, we need to ensure that the individual models are uncorrelated.
The higher the number of models we ensemble, the lower the variance. Then, can’t we just add as many models as possible into our ensemble to reduce the variance as much as possible? As $B \to \infty$, the variance of the ensemble tends to $\text{var}(\bar{z}) \to \rho \sigma^2$. That is, even with infinitely many models, the variance cannot go below $\rho \sigma^2$. This residual variance is due to the correlation among the models.
Simply increasing the number of models $B$ increases the correlation $\rho$ among the models, that is, the predictions of the individual models become more correlated. So, we need to increase $B$ but also reduce $\rho$. There are various ways to reduce $\rho$. The Random Forests algorithm uses one of those techniques.
Random Forests
The classical example of an ensemble model that uses bagging technique is Random Forests. In Random Forests, the individual models are decision trees, and it can be used for both classification and regression.
Warning
Note this is the first time, “decision tree” is mentioned. In general, the bagging technique can be applied to any model - linear regression, logistic regression, decision trees, neural networks, etc.
The randomness injected into the dataset creation process to generate bootstrap samples ensures that the individual trees are distinct from one another. In addition to it, at each node of every tree, the best split point is found based on a random subset of the features. But how does this ensure that the resulting trees are uncorrelated?
In practice, there will be a small set of strong predictors of the target and multiple moderate predictor variables. Every time we build a tree, the same features dominate the top nodes. In such cases, all the resulting trees look the same, and the predictions from those trees will be correlated. Random feature subsampling helps us avoid this and build trees with different features.
Random forest uses deep decision trees (without pruning), but it is less prone to overfitting because it uses the sampled (row and column-sampled) data and averages the results from multiple trees. Thus, pruning is not necessary.
Say we have a training dataset with $N$ observations and $p$ features. This training data is sampled both row-wise and column-wise in random forest.
- First, with replacement, we sample $N$ rows.
- We then build a tree on this data. At each node of the tree, we do column sampling from the total of $p$ features (without replacement). The number of features to be selected at every node is considered a hyperparameter. By a rule of thumb, the number of features to sample, $m$, can be calculated as $m=\sqrt{p}$ or $m = \log_2(p)$.
These two randomness ensures that the predictions from individual models are different, and the trees are uncorrelated.
Appendix
If you are interested in the mathematical details, proceed with this section. The section provides a mathematical reason for the lower bound of $A$ and the admissible range of $\rho$.
We have
\[A = \frac{1}{B} + \left(1-\frac{1}{B} \right) \rho\]We saw the upper bound for $A$, which is, $A \leq 1$. But what if $A$ is negative? For example, if $B=10$ and $\rho=-1$, then $A = \frac{1}{10} + \left(1-\frac{1}{10} \right) (-1) = -\frac{8}{10}$. In that case, the variance of the ensemble is negative, which is not possible. So, where is the catch? What ensures that $A \geq 0$?
The resolution is that not every value of $\rho \in [−1,1]$ is actually possible when we have $B$ identically distributed random variables with the same pairwise correlation.
We know that the covariance matrix is always positive semidefinite. That is, it must have non-negative eigenvalues. The covariance matrix of the random variables $(z_1, \dots, z_B)$ is
\[\Sigma = \sigma^2 \begin{bmatrix} 1 & \rho & \dots & \rho \\ \rho & 1 & \dots & \rho \\ \vdots & \vdots & \vdots & \vdots \\ \rho & \rho & \dots & 1 \\ \end{bmatrix}\]The eigenvalues of this matrix are $\sigma^2 (1-\rho)$ with multiplicity $(B-1)$ and $\sigma^2 (1 + (B-1)\rho)$ with multiplicity 1. Therefore, we must have
\[(1-\rho) \geq 0 \implies \rho \leq 1\]and
\[\begin{align*} 1 + (B-1)\rho \geq 0 & \implies \rho \geq \frac{-1}{B-1} \\ \\ & \implies (B-1)\rho + 1\geq 0 \end{align*}\]And we have
\[A = \frac{(B - 1)\rho + 1}{B}\]The numerator term $(B-1)\rho + 1\geq 0$ implies that $A \geq 0$. And the true admissible range for $\rho$ is
\[\frac{-1}{B-1} \leq \rho \leq 1\]References
- Francis Bach. Learning Theory from First Principles. The MIT Press, 2024. ISBN 9780262049443.
- Prathosh A. P. Classical Machine Learning (YouTube Playlist). YouTube.